Session state and Xdb tracking no longer required for rendering personalisation
Sun Feb 14, 2021 in Development , Sitecore using tags Sitecore , Hotfix , SessionStateHappy Valentine’s day

Background
So for quite sometime in order to be able to personalise a rendering on Content Delivery you’ve had to turn on Xdb tracking, even if you don’t want to use Xdb.
And by turning on Xdb Tracking, you have to turn on ASP.NET Session State, or it blows up.
- “Xdb.Tracking.Enabled” = true
- “Xdb.Endabled” = false
- ASP.NET Seession State - Enabled
Personalisation without Xdb?
What can you personalise with if you aren’t using Xdb? Well certainly you are going to be limited what you can personalise on, but you can still personalise on
- Request Url
- Request Headers
- Request Cookies
- Geo Location of Request
Think anything in the current request, but not their History like you would if had an Xdb profile, or current browsing session for previous pages visited available with session state.
What’s the problem with turning on Session State and Xdb Tracking
Well other than having to enable features that aren’t required, and it not being tidy.
Both of these two features cause cookies to be issued.
- SC_ANALYTCS_GLOBAL_COOKIE
- ASP.NET_SessionId
If you want to cache the response in a CDN then you can’t emit these request specific cookies at origin, the CDN won’t cache these responses. (Maybe with some custom logic to strip them?)
And trying to remove these cookies from being sent before the ASP.NET pipeline has flushed the response headers (after which can’t remove the headers as the client has already been sent the headers), can be quite tricky, especially for the ASP.NET Session State cookie which gets added to the response when the ASP.NET Session State object is accessed if it doesn’t already exist.
So trying to find the sweet spot in the ASP.NET pipeline when Sitecore has finished accessing the Session State object, and before ASP.NET has flushed the response headers, can be quite tricky. Or actually impossible to guarantee 100% of the time.
Solution - Hotfix for Sitecore 9.3
Sitecore Hotfix 448700 for Sitecore 9.3 fixes this.
As I understand it this issue might have been fixed in Sitecore 10 possibly, and has been backported, based on conversations, but I’ve not tested if this is fixed in Sitecore 10.
With this hotfix, gone is the need for Session State on Content Delivery and Xdb.Tracking.Enabled.
Gone is the need for the work arounds to remove these cookies from the response before they are sent.
And can still have renderings personalised based on the current request.

Sitecore Log4Net Lockup - Hotfix
Sun Jan 31, 2021 in Development , Sitecore using tags Log4Net , Sitecore , Hotfix , HangSitecore Log4Net Lockup - Hotfix & Don’t Share Appenders
This post is about a very rare elusive bug that caused the affected Sitecore instance to freeze up, as well not log anything which gave a clue what the problem was.
It was a combination of a bug in the Sitecore Log4Net code and additional Log4Net configuration that had been added (not OOTB) that caused Sitecore to lock up.

If you haven’t seen this issue, where a Sitecore instance locks up and you needed to restart IIS/Server, you probably won’t need this hotfix, but hopefully will get this hotfix rolled into a future version of Sitecore, so you’ll get the benefit then of hopefully never seeing this bug.
The Log4Net configuration recommendations are worth following though should you add any bespoke configuration.
As I mentioned it was a rare bug, and could go months without seeing the issue surface.
The affected Sitecore instance performed publishing and indexing operations, so was quite busy with lots of threads.
This issue has been seen in multiple Sitecore versions, up to at least Sitecore 9.3.
To get to the bottom of this elusive bug required a memory dump of the affected server. Sometimes restoring service is more important so not always possible to get a memory dump.
Even once that was done, required diagnostics to be added to work out what was causing the lock up/what was null, and more waiting for the issue to re-occur.
What was locking up/What was null?
Looking in the Sitecore.Logging.dll
And the “PatternParser” class, you can see if you pass in any of %C, %F, %L, %M, %l in your log4net conversionPattern configuration, it will call either the “ClassNamePatternConverter” or the “LocationPatternConverter”:
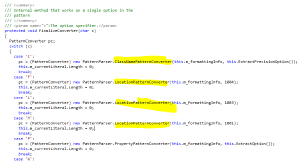
Both of these then make calls to get the Location information, which constructs a new “LocationInfo” instance.
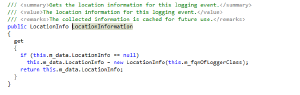
The constructor of the “LocationInfo” loops through the stack trace.
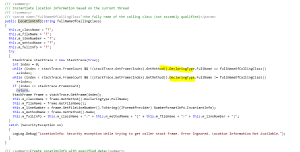
This code assumes that the DeclaringType is always going to be available, however it is possible that the stackFrame.GetMethod().DeclaringType might be null for lambda, which it was in our cases.
Possible workaround
One possible workaround before getting a hotfix would have been to not pass in these patterns which were causing the issues. However having the class name and location info of where an issue occurred is useful information.
Don’t share appenders
So Sitecore/Log4Net was failing to log when the stack trace had a Lambda which had a null DeclaringType.
Why was this causing Sitecore to hang?
Shouldn’t logging fail safe?
Well when a logger fails, it tries to log the issue to the root logger.
Our root logger was setup to also log to the same appender instance, also with the same ConversionPattern.
Due to the shared appender between loggers it was possible for deadlock to occur.
Setup/Key Facts
- RootLogger and PublishingLogger use the same appender instance
- DoAppend locks the appender which invoked it
- CallAppenders locks the logger which invoked it.
Scenario
- Publishing Logger call CallAppenders and DoAppend => gets the lock of Appender instance and PublishingLoggerObject
- RootLogger call CallAppeners and locks RootLoggerObject
- RootLogger calls DoAppender for Appender and tries to get the lock of the Appender Instance. But is already locked by PublshingLogger so has to wait until finishes.
- Whilst the PublishingLogger is trying to log, it gets an exception in LocationInfo, and so calls RootLogger to log the exception.
- RootLogger calls CallAppender and tries to get the lock of RootLoggerObject but is already locked
Deadlock

AzureFallbackAppender
Looking at App_Config\Sitecore\ExperienceContentManagement.Administration\Sitecore.ExperienceContentManagement.Administration.config
The AzureFallbackAppender is setup the same, for all the loggers to share the same appender.
“AzureFallbackAppender was designed specifically for Sitcore Support Package generator and it allowed us to collect the log files while generating the package. It was decided that only one AzureFallbackAppender remains for all kinds of logs, because of performance reasons.”
So whilst this isn’t recommended, the AzureFallbackAppender is a limited specific scenario, and issues haven’t been encountered with this.
Application Insights PAAS appender
Looking at the file in the Azure Websites project: App_Config\Sitecore\Azure\Sitecore.Cloud.ApplicationInsights.config
can see has the patch swaps out the default appends for the ApplicationInsights Log4NetAppender, so can see has a separate appender per logger as recommended.
So following the recommended practice.
Summary
- DeclaringType can be null for Lambdas
- Check for nulls
- Don’t share Log4Net appenders between loggers
Sitecore hotfix reference number
To monitor the progress of the related issue, please use reference number [437603]
Sitecore Incremental Publishing Edge Case
Thu Aug 13, 2020 in Publishing , Sitecore using tags Publishing , SitecoreWhat kind of publishing is this post about?
This post is about Incremental Publishing using the out of the box publishing mechanism, not the new Sitecore Publishing Service. There maybe reasons why you can’t use SPS just yet for your project.
Again if you are using a Smart or Full site publish this article won’t apply. But it’s recommended to setup a scheduled incremental publish.
This post relates to Sitecore 9.3, not reviewed if applicable for Sitecore 10 yet.
Great, so I know this is about Sitecore OOTB Incremental Publishing, and why it’s recommended to use this if SPS isn’t a good fit, tell me more about this edge case.
Edge Case
Disclaimer, this is an Incremental Publishing Edge Case issue where an item which should be published never gets published, most of the time you probably wouldn’t see this issue occur, and if you did spot something wasn’t published as it should, you’d just smart publish/republish the unpublished items & possibly their children to fix the issue.
You might possibly be thinking this could be a user error, something might not have been pushed through workflow, or not created until very recently (Always good to explore for technical issues before jumping to conclusions).
However if you have ruled out any user issues, and reviewed the logs and confirmed that the item should have been picked up in an Incremental Publish, you need to start looking for the Ghost in the Machine.
Ghost in the Machine

Working closely with Sitecore Support and with enough diagnostics data from the rare occurrences when this issue would rear it’s head, it was spotted that these items which wouldn’t get picked up by any incremental publish were saved around the time of the scheduled publishes.
Let’s explore what’s going on, and why an item saved very near an incremental publish operation on a rare occurrence might not get picked up.
Sql Column Specifications & Rounding
The “Properties” table stores the Last Publish date as a “String” including the ticks.
The “PublishQueue” table “Date” column stores the date in a Sql “Datetime” column which isn’t as precise and results in rounding.
As does the “Item” table “Created” and “Updated” columns which both use the same Sql “datetime” column, with the same rounding issue.
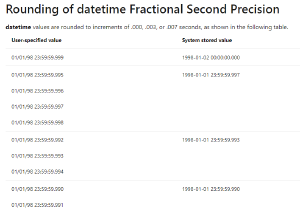
Due to these differences, say a publishing job was started with value From 14:00:00.017545Z, it would be rounded to 14:00:00.003ms, and would miss an item added at 14:00:00.000ms.
These millisecond round issues could cause an issue with an item not getting published, however that’s very small window for the issue to occur.
What happens when you save an item?
When you save an item, the items statistics get updated with the timestamp from C#/.NET in memory before getting persisted to the Database.
So the latency to get the record with the timestamp into the database could certainly be an issue/factor.
The datetime value used defaults to not storing the ticks/milliseconds on the item, and just defaults to datetime.ToString("yyyyMMddTHHmmss")
Truncating any milliseconds or ticks.
(See ItemStatistics.UpdateRevision, DateUtil.IsoNow, DateUtil.ToIsoDate)
So that could certainly be an issue, if saving an item towards the end of the Second (with a high millisecond value).
On save items are added to the publishqueue, with the date field values Updated, PublishDate, UnpublishDate, ValidFrom, ValidTo.
(See DefaultPublishManager.DataEngine_SavedItem, DefaultPublishManager.AddToPublishQueue, DefaultPublishManager.GetActionDateFields)
So that truncated second value gets copied across to the publishqueue table.
Example of an Edge Case
If I save an item at 2020-08-13T18:00:00.9881779+00:00
It will get saved as being created/modified at 2020-08-13T18:00:00.000,
and added to the publish queue
And I have an incremental publish kick off at 18:00, and picks up from the last publish 17:00:00.103-18:00:00.103 as a slight delay in starting. This doesn’t pick up the item which hasn’t been created yet at 18:00:00.9881779.
And the future publish operation won’t pick it up either as will look for items between 18:00:00.103-19:00:00.103, when it’s value will be saved as 18:00:00.000ms.
Work around
A work around would be to fix the query to include records affected by this precision/latency issue, at the expense of reprocessing some items more than once.
To do this can customise GetPublishQueueEntries method on the SqlDataProvider
public override List<PublishQueueEntry>GetPublishQueueEntries(DateTime from, DateTime to, CallContext context)
{
from = from.AddSecond(-1);
return base.GetPublishQueueEntries(from, to, context);
}
<configuration xmlns:patch="http://www.sitecore.net/xmlconfig/" xmlns:set="http://www.sitecore.net/xmlconfig/set/">
<sitecore>
...
<dataProviders>
<main>
<patch:attribute name="type" value="YourNamespace.CustomSqlServerDataProvider, YourAssembly" />
</main>
</dataProviders>
...
</sitecore>
</configuration>
Worst Case
Item statistics get updated at 17:59:59.999ms in C#
Item gets saved as 17:59:59.000ms but some latency before added to the database so doesn’t get added until after 18:00:00.103ms Item gets added to the publish queue with value 17:59:59.000ms
Publish Window by default queries for
18:00:00.103-19:00:00.103
with the 1 second fix would query for
17:59:59.103-19:00:00.103
Both of these would still miss the item at 17:59:59.000ms.
Improved Work Around
To round the start time query down to 0 milliseconds, and 0 ticks, can add the following line Credit Stack Overflow:
public override List<PublishQueueEntry>GetPublishQueueEntries(DateTime from, DateTime to, CallContext context)
{
from = from.AddSecond(-1);
from = from.AddTicks(-(from.Ticks % TimeSpan.TicksPerSecond));
return base.GetPublishQueueEntries(from, to, context);
}
So the new query would pick up even this more extreme edge case, with the query
17:59:59.000-19:00:00.103.
Summary
TL;DR; OOTB if you save an item at the same time an incremental publish kicks off, depending on the exact timing there is an edge case that it may never get published.
With a small work around in code you can ensure items saved around the time of a scheduled publish get picked up by the next incremental publish. At the expense of reprocessing some items/events. However this workaround isn’t in the form of an official hotfix, and would require extensive testing. No guarantees. Only consider this if are experiencing the issues described, and of course speak with Sitecore Support first.
Do I need this?
Well firstly you have to be using incremental publishing and scheduled publishing. And secondly unless you’ve spotted items not getting published, have enough editor activity that keep on encountering this issue on rare occasions, you probably don’t need it.
However if you are using incremental and scheduled publishing, and have spotted odd issues with items not getting published, and can’t explain them due to user error. This might help explain the Ghost in the machine and a work around. But don’t apply this fix if you don’t need it.
And if you do implement this fix you’ll have to test this customisation, as not an official hotfix, and no guarantees. Just a suggestion that this could help if suffering from this particular issue. And if was implemented incorrectly could lead big problems, e.g. re-processing of events. So you’ve been warned.
Longer term
Longer term I’m sure SPS will further improve, and will be able to be used by more customers. At which point Smart Publishing becomes fast enough, we don’t need the old incremental publishing.
If there was to be a fix for incremental publishing, the window could be reduced by calculating and storing a last modified time at Sql Server level with millisecond/timestamp precision, rather than using C# and truncating down to the second level with the latency to insert it into the database. As well as using the DateTime2 column format rather than DateTime with it’s millisecond rounding precision issues. However, this is quite a schema change for an edge case, so the work around will suffice for those that are affected.
Sitecore Bug Tracking Reference
Sitecore Bug Tracking Reference #397573.
Final Disclaimer
Don’t use this work around unless you are experiencing the issues described, and even then perform your own testing, no guarantees.
These code samples haven’t been tested, and just give the gist of the fix required.
Work with Sitecore Support to confirm you are experiencing the issue described, as this customisation has a cost to it, and could have negative implications to your solution even if implemented correctly, and even more negative implication if incorrectly implemented.